
The following section describes the procedures used to collect, process, and analyze Reddit posts about negative psychotherapy experiences. We outline the steps from data collection through text classification and extraction, followed by NLP-based analyses and integration with qualitative frameworks. Our approach combines automated LLM techniques with manual validation and interpretation to ensure methodological rigor and contextual relevance.
Data collection
We collected publicly accessible Reddit posts and comments from 100 mental health-related subreddits between 2022 and 2024, as this period reflects recent and thematically relevant user experiences. Data were extracted using the Python Reddit API Wrapper (PRAW)42. Posts and their associated comments were only included if the post contained at least one of the following keywords: therapist, psychotherapist, psychologist, treatment, therapeutic professional, therapy, psychotherapy, dissatisfied, negative experience. The selection of keywords was kept broad to minimize search term bias for subsequent clustering. Subreddits were chosen to span a wide range of mental-health topics and therapeutic approaches, thereby reducing subreddit-specific linguistic or thematic bias. The selection process primarily targeted communities centered on mental health conditions (e.g., r/Depression, r/CPTSD, r/BingeEatingDisorder), ensuring comprehensive coverage of all ICD-10 disorder categories, as well as subreddits focusing on therapy and therapeutic approaches (e.g., r/TalkTherapy, r/CBT, and r/Psychoanalysis) to capture discussions about treatment experiences and methodologies. In total, 54,056 posts and 467,163 comments (521,219 in combination) met the inclusion criteria. Ethical considerations, de-identification, pseudonymization, and other privacy safeguards are provided in the ethical considerations section.
Sample post information
Across the 100 subreddits, the median number of posts per subreddit was Mdn = 525 (Q1 = 215; Q3 = 848), while the median number of comments per subreddit was Mdn = 3489 (Q1 = 1443; Q3 = 6448). The median word count of a post was Mdn = 243 (Q1 = 138; Q3 = 418), whereas comments had a median word count of Mdn = 47 (Q1 = 21; Q3 = 99).
User information
From 5362 users who reported dissatisfaction, we extracted demographic details they had disclosed in their posts and comments (see Ethics Considerations section for rationale and safeguards). The number of users was determined via unique usernames, which were pseudonymized during processing. However, multiple accounts by the same individual cannot be fully excluded. After de-identification, age information for still n = 1437 users was maintained. Ages were grouped into categories to prevent individual identification through exact age details. The median age category was Mdn = mid-twenties (Q1 = early twenties; Q3 = early thirties), ranging from young adult to end seventies. The most frequent categories were early twenties (n = 456; 31.7%), and early thirties (n = 265; 18.4%). Sample information on gender, education, residence, disorder categories, treatment approaches, and therapists’ gender is shown in Table 1.
Table 1 Sample user informationData preprocessing and building chunks per user
We first sorted and aggregated all posts and comments chronologically for each user to provide the LLM with contextual information for classification. This approach ensured that references to earlier posts and comments by the same user (e.g., when a comment refers to a therapist as “she” without explicitly mentioning the profession) remained interpretable. Without this aggregation, relevant contextual information would not be considered. For the purpose of this study, we define a chunk as a contiguous sequence of a user’s posts and comments that is processed together as a single unit by the model. Given the limited context length of the LLM, we set a maximum of 2000 tokens (basic text units processed by the model) per chunk. If this limit was exceeded, a new chunk was created. We limited the number of chunks per user to a maximum of ten to prevent the results from being overly influenced by a few individual users.
Defining psychotherapy dissatisfaction
We defined personal psychotherapy dissatisfaction as a feeling of being dissatisfied or discontent with one’s own psychotherapy experience. Negative experiences may be related to the therapy setting, the therapist (e.g., their characteristics or behaviors), the therapeutic process, the therapeutic approach, the patients’ behavior in therapy, stagnation or deterioration in progress, costs, or access to psychotherapy. Psychotherapy dissatisfaction is specifically related to one’s own experience in therapy. This definition guided the subsequent classification process and the extraction of relevant text passages.
Classification
We classified whether the chunks were related to psychotherapy dissatisfaction using the gpt-4o-mini-2024-07-18, at the time of the analysis, a cutting-edge LLM offering relatively low inference duration and cost, accessed via the OpenAI API. The model was provided with specific instructions, including our definition of psychotherapy dissatisfaction (see Supplementary Note 1 for the full prompt). We set the temperature parameter to 0.0 to achieve a high level of reproducibility of the classification.
Then, we selected a stratified random sample of 1000 chunks, ensuring that all sub-forums were proportionally represented to reduce biases across different sub-forums. Of these, 50% had been pre-rated as “Yes” and 50% as “No” by the LLM. We increased the proportion of “Yes”-rated chunks within this sample, as these posts were included in the subsequent analysis, whereas “No”-rated chunks were not. A trained human rater, an undergraduate psychology student specializing in clinical psychology and psychotherapy, independently rated the sampled posts. The rater was blinded to the model’s classification and received specific instructions and training before annotation. We then calculated Cohen’s kappa to assess the agreement between human and model classifications.
Extraction of text passages
Since the chunks did not exclusively focus on psychotherapy dissatisfaction but also covered other topics, the next step was to extract text passages, defined as coherent segments of a chunk, specifically related to psychotherapy dissatisfaction. The gpt-4o-2024-11-20 model was used to filter all text passages based on the previously defined criteria for psychotherapy dissatisfaction (see Supplementary Note 2 for the full prompt). This model offers higher accuracy, improved contextual understanding, and enhanced reasoning capabilities, but at the expense of increased computational cost and longer inference times compared to the gpt-4o-mini-2024-07-18. The same trained human rater as in the previous step independently extracted text passages from a stratified random sample of chunks, ensuring that all sub-forums were proportionally represented. The rater did not know which and how many passages had been extracted by the GPT model. We evaluated the overlap between LLM- and human-extracted passages using ROUGE (Recall-Oriented Understudy for Gisting Evaluation). ROUGE-1, ROUGE-2, and ROUGE-L assess unigram, bigram, and longest common subsequence overlap, respectively, and are widely used in summarization and information extraction tasks43.
Clustering
The text passages extracted by the LLM were further processed for clustering. We applied clustering, an unsupervised learning technique, to group the text passages based on their content. First, contextual embeddings were generated using the SentenceTransformer model all-mpnet-base-v244. This model is well-suited for short texts, such as our text passages, and for computing text similarities, which is essential for clustering.
Distance measures in high-dimensional spaces become less precise, which is why dimensionality reduction should be applied first to improve cluster quality. Therefore, as the second step, we reduced the dimensionality of the input embeddings using UMAP, a non-linear dimensionality reduction algorithm45. Third, we applied HDBSCAN46, a hierarchical density-based clustering algorithm designed to identify dense regions (clusters) within data. Outliers are defined as text passages that HDBSCAN did not assign to any cluster due to insufficient local density.
Fourth, we conducted an internal cluster validation using the silhouette score47 and the Calinski-Harabasz index48, complemented by a brief manual review, to assess the quality of the identified clusters and compare different clustering solutions (see Supplementary Table 1 for parameter settings). Since no ground truth labels exist for the construct of psychotherapy dissatisfaction, an external validation was not possible. Additionally, we briefly manually reviewed the identified clusters. After considering the two indices and the brief manual review, we decided on the best-fitting solution.
Fifth, two raters (a trained psychology student who had also participated in earlier rating tasks, and a PhD candidate in psychotherapy research) labeled the identified clusters by manually reading the associated text passages of each cluster through inductive thematic analysis49. In cases of uncertainty, the raters referred to the topics generated through BERTopic50, discussed their labels, re-examined the associated text passages, and reached a consensus on the final cluster names.
Topic modeling
Topic modeling aims to identify latent themes in text data and organize them into interpretable topics. BERTopic generates coherent topic representations by assigning one topic to each cluster using a class-based TF-IDF procedure50. TF-IDF, the product of term frequency and inverse document frequency, highlights important n-grams within a topic. In BERTopic, embeddings are first created, then reduced in dimensionality, and subsequently clustered. Since we had already completed these steps with optimized parameters in clustering, we directly applied the newly generated and extracted topics, with each topic consisting of n-grams ranging from unigrams to trigrams. Topic modeling was performed to gain a deeper understanding of the respective clusters and has already been successfully employed for psychotherapy research39.
Pre-determined clusters and meta-categories
We aimed to assess the extent to which the newly generated clusters align with the categories identified in previous studies. To achieve this, we used the clusters and meta-categories from a qualitative meta-analysis20, which consists of 21 meta-categories grouped into four clusters. In the following, we will call these pre-determined clusters and pre-determined meta-categories. The four pre-determined clusters were named Therapists’ Misbehavior, Hindering Aspects of the Relationship, Poor Treatment Fit, and Negative Impacts of Treatment.
Two authors independently categorized the newly generated clusters into the pre-determined meta-categories. Then, they compared their assignments, and in cases where they disagreed, they re-evaluated the assignments through discussion to reach a final decision. If no consensus was reached, the cluster was assigned to a separate “no fit” category. After all clusters were categorized, the clusters in the “no fit” category were re-examined to search for potential overlaps that could lead to the formation of a new category.
User-level analysis
We analyzed the presence and variety of patient contributions across clusters, focusing on the number and variety of dissatisfaction reasons reported by individual users.
To achieve this, we calculated the average number of text passages per individual and the average number of clusters each user contributed to. Additionally, we examined the distribution of the pre-determined clusters across individual users and assessed the frequency of cluster co-occurrences within users.
Sentiment analysis
We aimed to identify which of the newly generated clusters and the pre-determined clusters were associated with the strongest negative affect. To measure negative, neutral, and positive affect, we used the roBERTa sentiment model (https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest)51. The model was trained on ~124 million tweets and fine-tuned using the TweetEval benchmark52. Our full analytical pipeline, from data collection to clustering and interpretation, is depicted in Fig. 1.
Fig. 1: NLP-mixed-methods pipeline for extracting and analyzing psychotherapy dissatisfaction.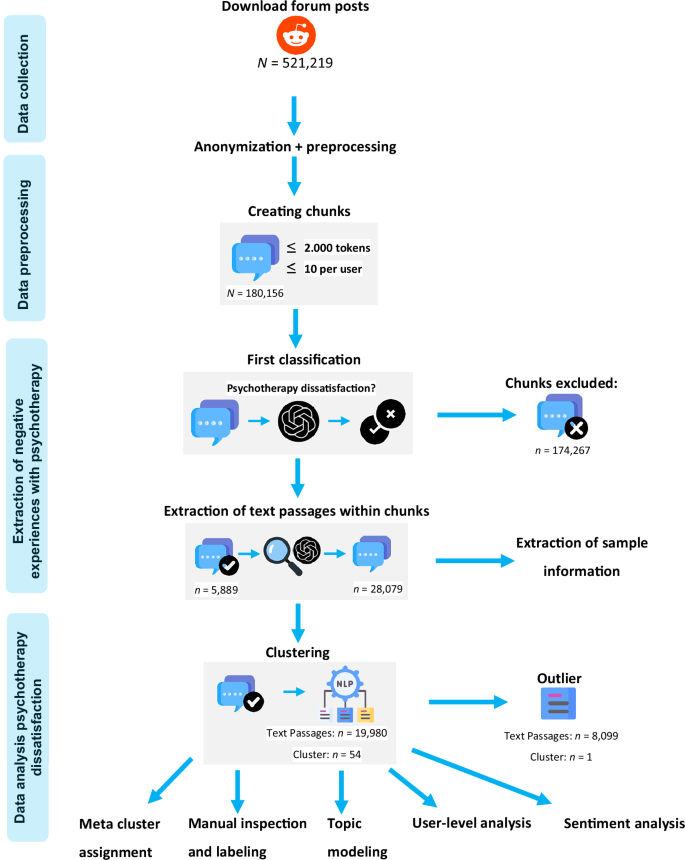
Blue rounded boxes represent preprocessing steps, while icons indicate the respective task. NLP refers to natural language processing. Forum posts were anonymized and aggregated into chunks, defined as consecutive aggregated posts and comments from the same Reddit user. Tokens are the basic text units processed by the model, typically corresponding to short words or word fragments. Chunks classified as relevant were further divided into text passages. A text passage is a segment within a chunk that specifically relates to dissatisfaction with psychotherapy. Subsequent steps included meta cluster assignment, manual inspection and labeling of clusters, topic modeling, user-level analysis, and sentiment analysis. Icons sourced from Flaticon.com.
Ethical considerations
We collected publicly accessible Reddit posts and comments between 2022 and 2024 using PRAW42 while adhering to ethical and legal frameworks, including international and national laws, Reddit’s Privacy Policy, and Subreddit Guidelines.
Health-related subreddits can serve as spaces for vulnerable groups, requiring researchers’ heightened ethical sensitivity to prevent reinforcing stigmatizing narratives53. Although Reddit posts are publicly visible, users typically use system-generated or self-chosen usernames instead of their real names. While sharing personally identifiable information about others is not allowed, there is still a risk that someone could be re-identified53,54. Direct quotations or shared context may risk re-identification through reverse searches, especially when personal information is embedded in users’ account histories.
To avoid reinforcing stigma and to safeguard participants’ privacy, we implemented additional measures for users’ data protection during data collection and processing. We did not collect data from any subreddits where the moderators, rules, or FAQs prohibit the use of data for research purposes. To further minimize traceability risks, no other profile information or metadata, such as user IDs was collected.
We oriented our de-identification process toward a previously published method41. User privacy was further protected through a two-step automated and manual de-identification pipeline. Personally identifiable information was removed using the GLiNER model55 by identifying and deleting named entities such as names, email addresses, and specific locations. User tags, physical addresses, telephone numbers, URLs, and other linked content (e.g., marked with “@”) were also removed. Direct quotations were paraphrased. In addition, any self-reported ages were categorized into broad categories (e.g., early twenties) rather than recorded as exact values. Moreover, the original usernames were replaced with anonymized identifiers. Posts and comments from users whose accounts had already been deleted before data collection were excluded from the analysis. A subsequent manual evaluation verified the efficacy of the anonymization procedures, and any remaining information we found that could facilitate identification was removed. Data were stored on secure, access-controlled internal servers with restricted project-team access.